
Uno de los principales temas a los que Google le ha declarado incansablemente la guerra durante años es al contenido duplicado, para Google el término contenido duplicado se refiere cuando existen páginas que teniendo URL diferente tienen el mismo contenido. También existen otros casos en los que los buscadores consideran contenido duplicado como son:
- Contenido diferente pero con urls idénticas entre si
- Los IDS de sesión suelen ser creador de contenido duplicado. Esto ocurre cuando cada usuario que visita un sitio web se le asigna un identificador de sesión diferente que se almacena en la url.
- Páginas con HTTP, si nuestro sitio utiliza el código de encriptación SSL, podemos acabar con una copia exacta en nuestra versión que utiliza htpp.
- Paginas seguidas por una paginación: esto suele ocurrir en aquellas páginas que comparten la misma title y metadescripción.
- Identicos Title y meta description en diferentes páginas de la misma web.
- Tu servidor está configurado para mostrar el mismo contenido para el subdominio con www o para el protocolo https.
Por ello, y para evitar este grave problema en febrero de 2009 los principales buscadores como Google y Yahoo dieron con el santo grial, las tan conocidas etiquetas Rel=Canonical.
¿Qué es y para que se utiliza la “Rel= Canonical”?
La etiqueta “Rel= Canonical” se utiliza para decirle a Google que una url es equivalente a otra y que solo debe indexar una de ellas.
Por ejemplo, si tenemos la url-página1 y la url-página2, siendo esta última una copia de la primera, mediante la etiqueta rel=canonical le diremos al buscador que la url que tiene que considerar y que tiene que indexar es la url-página1.
¿Donde se coloca la “Rel=Canonical”?
La etiqueta “Rel=Canonical” debemos de colocarla entre las etiquetas de inicio <head> y el cierre </head> ya que de otra manera los buscadores ignorarían la etiqueta y por lo tanto seriamos penalizados por contenido duplicado. Siguiendo el ejemplo anterior, habrá que colocarla en ambas páginas: url-página2 y url-página1. Si fuesen 3 o más, habría que colocarla en TODAS las páginas que pudiesen ser consideradas contenido duplicado.
El link se pondría entre las etiqueta de la cabecera de la siguiente manera:
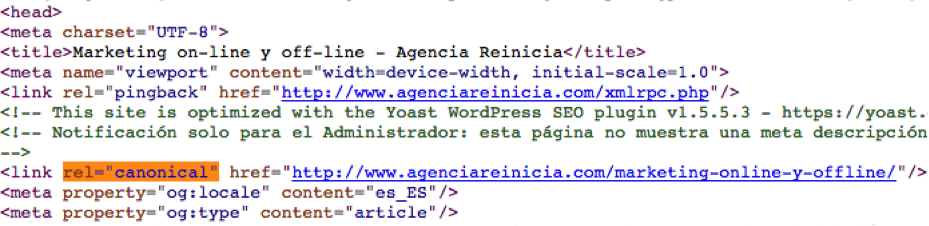
Canonicalización en caso de diferentes dominios
Cuando una misma empresa tiene www.miempresa.com/es y www.miempresa.es ambas en español pero con diferentes dominios, deberemos escoger el mejor dominio por ejemplo www.miempresa.com/es y añadir la etiqueta en www.miempresa.es de la siguiente manera:
<link rel=”canonical” href=”https://www.mipagina.com/es” />
Con esto le diremos a Google que la página del dominio que tiene que indexar es www.miempresa.com/es y no www.miempresa.es. Por supuesto, esta etiqueta habrá que añadirla en las páginas que pudieran ser consideradas duplicadas de ambos dominios, NO sólo en una de ellas.
Principales errores en el uso de las Rel=Canonical
Algunos de los errores más comunes a la hora de utilizar la etiqueta rel=canonical desde su aparición son:
- Utilizar de manera equívoca direcciones de url relativas en lugar de direcciones de url absolutas:
- Incorrecto: <link rel=”canonical” href=”/marketing-online-y-offline/”/>
- Correcto: <link rel=”canonical” href=”https://www.agenciareinicia.com/marketing-online-y-offline/”/>
- Usar la etiqueta en el cuerpo de la página, es decir, en el <body>: como hemos dicho anteriormente la etiqueta rel=canonical debe ir entre las etiquetas de inicio <head> y el cierre</head>.
- Apuntar a la primera página de una serie paginada. Supongamos que tenemos un artículo con varias páginas:
www.ejemplo.com/articulomanzana/pagina1,
www.ejemplo.com/articulomanzana/pagina2,
www.ejemplo.com/articulomanzana/pagina3
Colocar la url canonical en la pagina 2 o 3 a la página 1 no es correcto porque no son contenido duplicado, el uso de rel=”canonical” en este caso haría que las páginas 2 y 3 no se indexaría, para estos casos es recomendable utilizar el marcado paginación rel = «prev» y rel = «next».
- Tener varias copias de la etiqueta.
- Cuando podemos acceder a nuestra web a través de diferentes url´s como puede ser: https://www.mipagina.com, https://mipagina.com, https://www.mipagina.com/index.php, aunque para Google estas url´s las considera diferente, muestran el mismo contenido y por lo tanto nos van a penalizar por contenido duplicado. Por ello, si nos encontramos ante una situación similar es conveniente escoger la mejor versión que en este caso es https://www.mipagina.com y redireccionar las otras dos versiones evitándonos con ello que Google determine cual es la mejor versión. Pero en este caso, la solución NO es indicar la canonical, sino hacer una redirección 301 completa desde el dominio «secundario», por ejemplo, www.miempresa.com, al dominio preferido, por ejemplo, miempresa.com.
Con esta etiqueta el quebradero de cabeza por el contenido duplicado ya no debe de ser un problema para un correcto posicionamiento de tu web, y por fin podemos decir que le hemos cogido la delantera al mismo, aunque no podemos nunca perderle de vista. Esperamos que con este artículo te hayamos aportado los conocimientos necesarios para que tu web salga triunfadora frente al malicioso contenido duplicado.
